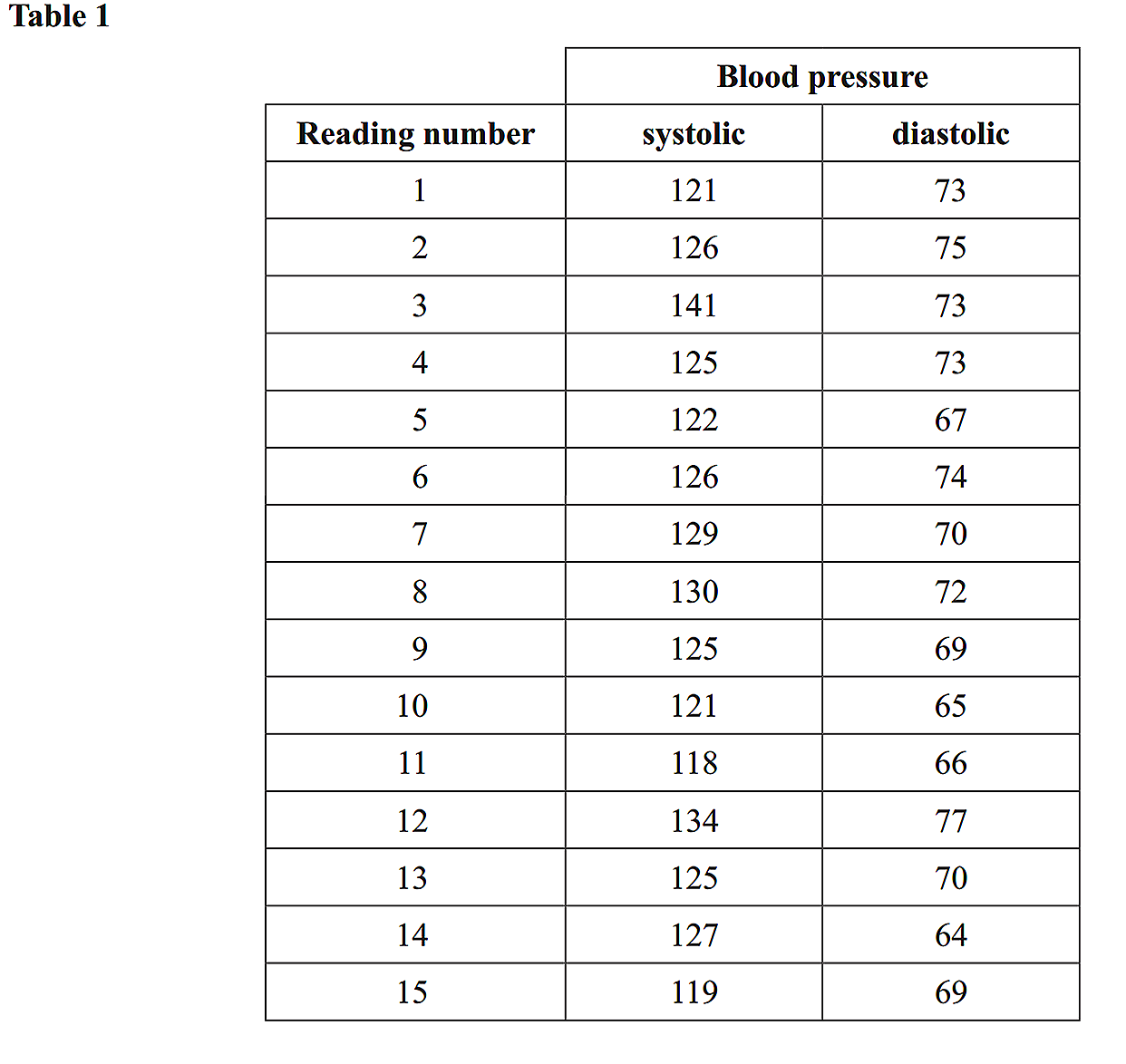
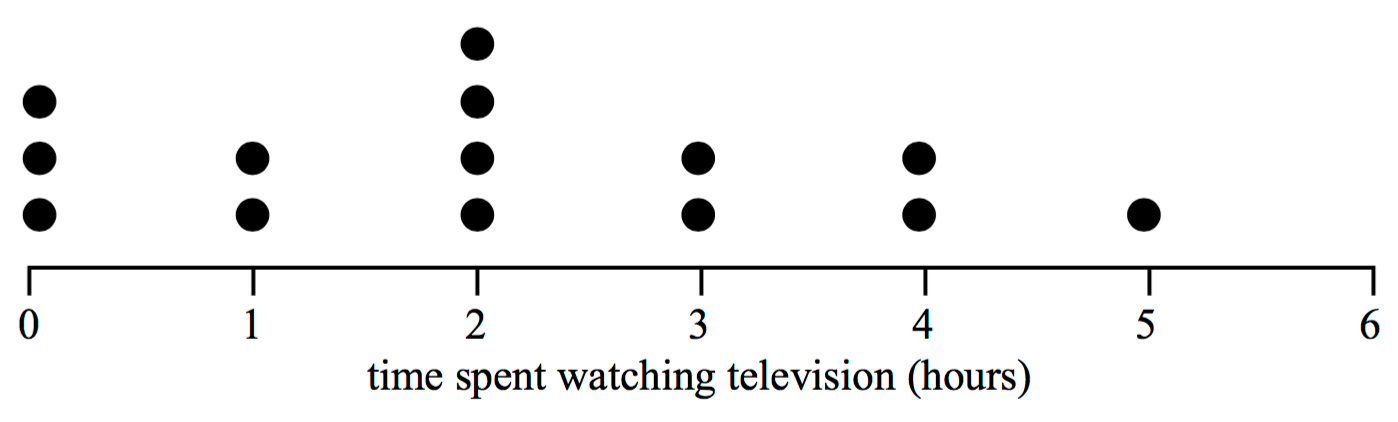
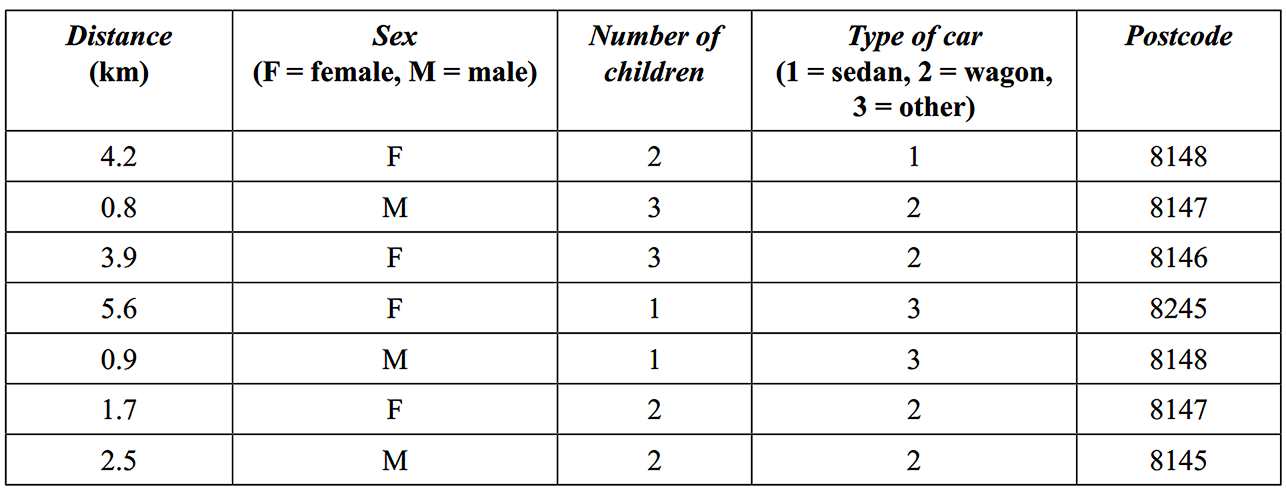
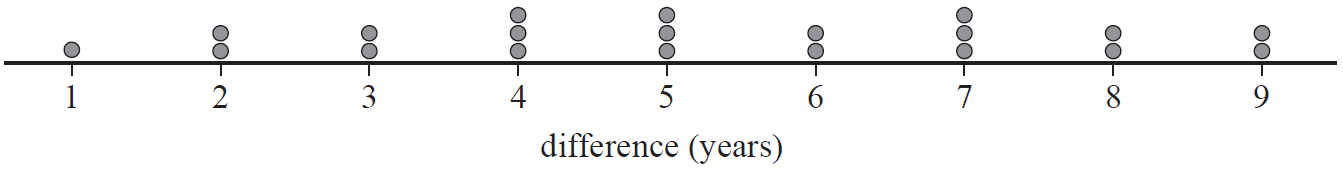Table 1, below, shows the prices in dollars, price, for a sample of 20 homes sold in an inner Melbourne suburb during 2017.
The type of home sold is either an apartment or a house.
Table 1
\begin{array}{|c|c|}
\hline \rule{0pt}{2.5ex}\quad \ \textit{Price(\$)}\quad \ \rule[-1ex]{0pt}{0pt}& \textit{Type} \\
\hline \rule{0pt}{2.5ex}350\,000 \rule[-1ex]{0pt}{0pt}& \ \ \text{apartment}\ \ \\
\hline \rule{0pt}{2.5ex}490\,000 \rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}500\,000 \rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}620\,000 \rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}720\,000 \rule[-1ex]{0pt}{0pt}\rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}830\,000 & \text{apartment}\\
\hline \rule{0pt}{2.5ex}875\,000 \rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}995\,000 \rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}1\,100\,000 \rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}1\,520\,000 \rule[-1ex]{0pt}{0pt}& \text{apartment}\\
\hline \rule{0pt}{2.5ex}800\,000 \rule[-1ex]{0pt}{0pt} & \text{house}\\
\hline \rule{0pt}{2.5ex}840\,000 \rule[-1ex]{0pt}{0pt}& \text{house}\\
\hline \rule{0pt}{2.5ex}920\,000 \rule[-1ex]{0pt}{0pt}& \text{house} \\
\hline \rule{0pt}{2.5ex}920\,000 \rule[-1ex]{0pt}{0pt}& \text{house}\\
\hline \rule{0pt}{2.5ex}1\,010\,000\rule[-1ex]{0pt}{0pt} & \text{house}\\
\hline \rule{0pt}{2.5ex}1\,263\,000 \rule[-1ex]{0pt}{0pt}& \text{house}\\
\hline \rule{0pt}{2.5ex}1\,398\,000 \rule[-1ex]{0pt}{0pt}& \text{house}\\
\hline \rule{0pt}{2.5ex}1\,460\,000\rule[-1ex]{0pt}{0pt} & \text{house}\\
\hline \rule{0pt}{2.5ex}1\,540\,000 \rule[-1ex]{0pt}{0pt}& \text{house} \\
\hline \rule{0pt}{2.5ex}1\,540\,000 \rule[-1ex]{0pt}{0pt} & \text{house}\\
\hline
\end{array}
- Find the median, in dollars, of the variable price. (1 mark)
--- 1 WORK AREA LINES (style=lined) ---
- State whether the variable type is numerical, nominal or ordinal. (1 mark)
--- 1 WORK AREA LINES (style=lined) ---
-
- Complete the table below by finding the standard deviation, to the nearest whole number, for the sale price of apartments in the sample. (1 mark)
--- 0 WORK AREA LINES (style=lined) ---
- Table 2
\begin{array}{|c|c|}
\hline \rule{0pt}{2.5ex} \quad \ \ \textbf{Type of home} \quad \ \ & \quad \textbf{Standard deviation of} \quad \\
& \rule[-1ex]{0pt}{0pt}\textbf{sale price (\$)}\\
\hline \rule{0pt}{2.5ex}\text{house} \rule[-1ex]{0pt}{0pt}& 300\,911 \\
\hline \rule{0pt}{2.5ex}\text{apartment} \rule[-1ex]{0pt}{0pt}& \\
\hline
\end{array} - Using the information in Table 2, comment on the relative spread in the distribution of the sale prices of houses compared with apartments in this sample. (1 mark)
--- 3 WORK AREA LINES (style=lined) ---
- Complete the table below by finding the standard deviation, to the nearest whole number, for the sale price of apartments in the sample. (1 mark)
- Table 3, below, shows the percentage of houses and apartments with prices in the given ranges. Some information is missing.
- Use the data from Table 1 to complete Table 3.
--- 0 WORK AREA LINES (style=lined) ---
- Table 3